
Managing AWS EKS clusters at Scale
Running Kubernetes (K8s) clusters in Amazon Web Services (AWS) is an easy process thanks to Elastic Kubernetes Services (EKS). Managing them at scale, however, is an entirely different process as complexity starts to increase.
When you are using EKS at scale, or any cloud service for Kubernetes, you are no longer monitoring a single cluster’s health and costs. You are dealing with multiple workloads, policies that need to be consistent across your environments, governance, security, and compliance.
In this article, we will explore what are the main strategies you will need to implement in order to successfully manage AWS EKS clusters at scale, and some of the best practices of doing so.
TL;DR:
1. Implementing consistency and standardization
When you start with any cloud service, what you do is you usually go to the console, and start doing ClickOps to understand what you can configure and how you can configure the service. A single cluster deployed manually might be fine if you are not planning to create others, but repeating the process of manually creating them will cause major headaches later. You will most likely have inconsistencies between them, and end up doing endless cycles of firefighting to solve all the issues you will encounter.
By using Infrastructure as Code (IaC), you will avoid this issue. There are many tools like Terraform, OpenTofu, Pulumi, CloudFormation, or Crossplane that let you define exactly how a compliant EKS cluster would look like in your organization, taking into account networking, IAM, autoscaling groups, and all the other resources you might need for your clusters. Leveraging IaC, however, introduces a different set of issues, that are usually solved by using an infrastructure orchestration platform because it gives you the ability to enable policy as code to ensure your infrastructure resources are compliant, manages the state for you (if you are using a stateful IaC tool), enables a thorough CI/CD process for your deployments with multi-IaC workflows, and more.
Enabling GitOps with an infrastructure orchestration platform for your infrastructure deployment and its configuration, and leveraging GitOps for your application deployments using tools like ArgoCD or Flux, ensures that your infrastructure changes are handled with the same rigor as application deployments.
In this way, your cluster creation process turns into a repeatable and predictable process, instead of a manual effort. This highly reduces the chances of misconfigurations, and gives your engineers time back to focus on the things that matter.
2. Scaling without wasting resources
When you are talking about enterprise scale, you don’t have to choose between efficiency and performance. Even though it is tempting to overprovision resources to be safe, if you multiply this across hundreds of clusters, this safety net actually translates into an expensive waste, that makes no sense whatsoever.
Autoscaling strategies make a real difference here. Horizontal and vertical pod autoscalers can help you with right-sizing services automatically, while tools such as Cluster Autoscaler can adjust node counts in response to demands.
Karpenter offers faster scaling, and also gives you the ability to use lower-cost spot instances, which is very useful when your workloads can tolerate interruptions.
The real value of scaling comes from tuning all of these tools inside your Kubernetes environments, so you maintain the performance you need while keeping your costs in check.
3. Implementing policy as code
Open Policy Agent (OPA) is a powerful policy engine that enables you to streamline your policy management across your workflows. It can be easily paired with IaC, to deny the creation of certain resources or certain resource parameters, enabling you to provision your EKS clusters, without being afraid that something will go wrong during this process.
At the same time, OPA can be used inside your Kubernetes clusters, through Gatekeeper, to enforce policies for your Kubernetes resources, making it easy to ensure that, for example:
- All images must be from approved repositories
- Restricting the usage of the latest image tag
- Ensuring that all pods have resource limits for CPU and memory
- All namespaces should have particular labels
- And more
Apart from OPA Gatekeeper, there is another tool that can be used for policy enforcement inside your Kubernetes clusters called Kyverno, but this tool works exclusively with Kubernetes applications. OPA uses the Rego language to define policies, while Kyverno policies are written in YAML, making them easier for teams that are already familiar with K8s manifests.
Here are some example policies that disallows tags:
In any case, you cannot manage EKS at scale, without enforcing policies at the infrastructure level with something like OPA. When you are dealing with multiple clusters, in different environments, and multiple teams deploying workloads, you need a way to ensure that every deployment meets your organization’s standards.
Shifting-left at both the infrastructure and application deployment levels, ensures that no matter who deploys a workload, where it runs, or how quickly your EKS footprint grows, you are respecting all the operational best practices. In this way, you gain a safety net that enables your K8s ecosystem to scale properly.
4. Scaling security
To keep security in check, many organizations adopt IAM Roles for Service Accounts (IRSA) to enforce least privilege access. IRSA gives you the ability to manage credentials for your applications, in a similar manner that EC2 instance profiles do it for EC2 instances.
With IRSA you don’t need third party solutions such as kube2iam, you enable auditability because every action can be easily seen in CloudTrail, and ensure credential isolation.
When it comes to security, you always need to use security vulnerability scanners to ensure that your container images, or even your infrastructure don’t introduce vulnerabilities inside your environment. Tools such as Trivy, Anchore, and others help you identify risks, before they reach your production environment, and give you enough time to fix the underlying issues.
5. Implementing observability
When there are issues inside your clusters, you need more than intuition and a mastery of the CLI to find the cause, especially when you are juggling with K8s at scale. Observability is an important pillar in the Software Development Life Cycle (SDLC), and for Kubernetes this can be even more important, as your clusters have many moving parts.
Having a unified observability strategy allows you to understand, at a glance, what is the health status of your K8s environments.
By taking advantage of kubectl top you can easily collect basic metric data, such as CPU and memory usage for nodes and pods. While this is fine for ad-hoc troubleshooting, it is not enough for running EKS clusters at scale.
Using Prometheus combined with Thanos can aggregate metrics for every cluster you have, while leveraging Grafana can provide dashboards that reveal trends and anomalies. This setup allows you to move to a full analysis, letting you also implement proactive alerting.
6. Using Lens Kubernetes IDE to manage EKS clusters at scale
Lens K8s IDE is a Kubernetes IDE that helps you connect, observe, and manage Kubernetes clusters in a graphical environment. You can see at a glance what is happening inside your clusters, and take actions accordingly from the UI.
With Lens K8s IDE you can easily attach to your pods, open shells to them, see their logs, and even port-forward to your services to understand if your applications are working properly.
Apart from that, if you are using CRDs or Helm charts, you can easily manage them directly from Lens K8s IDE:
In the CRD view you can easily see your Policy as Code resources, and quickly understand which policies are active, their enforcement status, and how they are applied across namespaces.
For EKS specifically, you can use Lens to connect to all of your Kubernetes clusters, based on your user’s access with a single click.
You will just need to specify how you want to configure your AWS profile and then you are good to go; all of your EKS clusters will be loaded dynamically, and as soon as a new EKS cluster is created, you will automatically have access to it.
In addition to this, Lens K8s IDE has an AI powered assistant called Lens Prism, that can help you understand what is happening inside of your clusters, offering insights on how to move forward in case you have issues. In this way, you can save a lot of time, and even if you don’t have that much experience with Kubernetes, you will be enabled with a powerful mechanism to overcome problems.
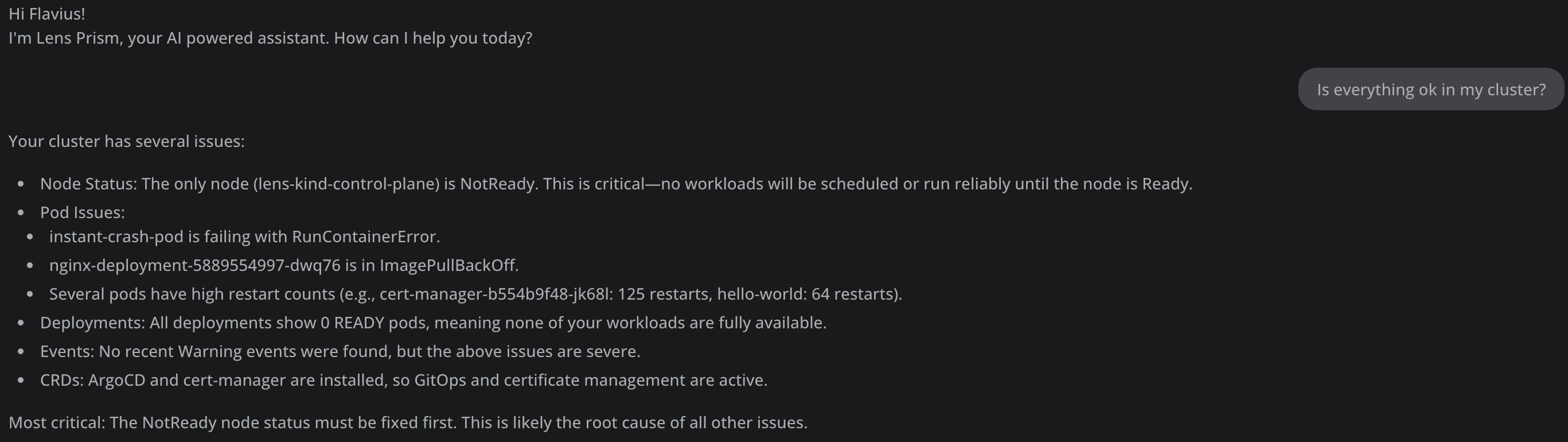
If you want to see how to use Lens Prism to fix the most common Kubernetes errors, check out this article.
Note: Lens EKS integration and Lens Prism are available starting from the Plus/Pro tiers. To learn more about our pricing click here.
Key points
Managing EKS clusters at scale starts with how you create your EKS clusters, and then takes into account all the aspects related to security, governance, and compliance, all while keeping costs under control.
It can be really hard to juggle between multiple Kubernetes clusters and understand how their performance is affected, and that’s where Lens K8s IDE with its powerful built-in observability, one-click EKS integration, and Lens Prism comes in to help.
If you want to leverage EKS management at scale, download Lens K8s IDE today.